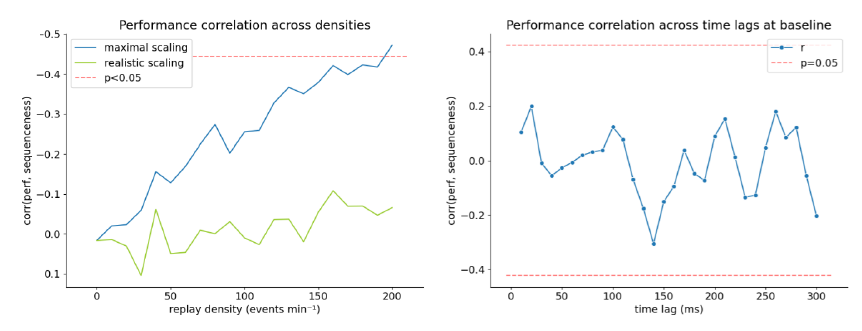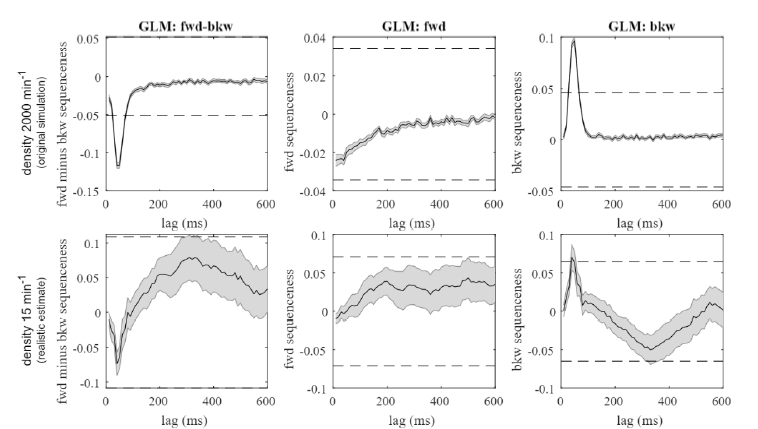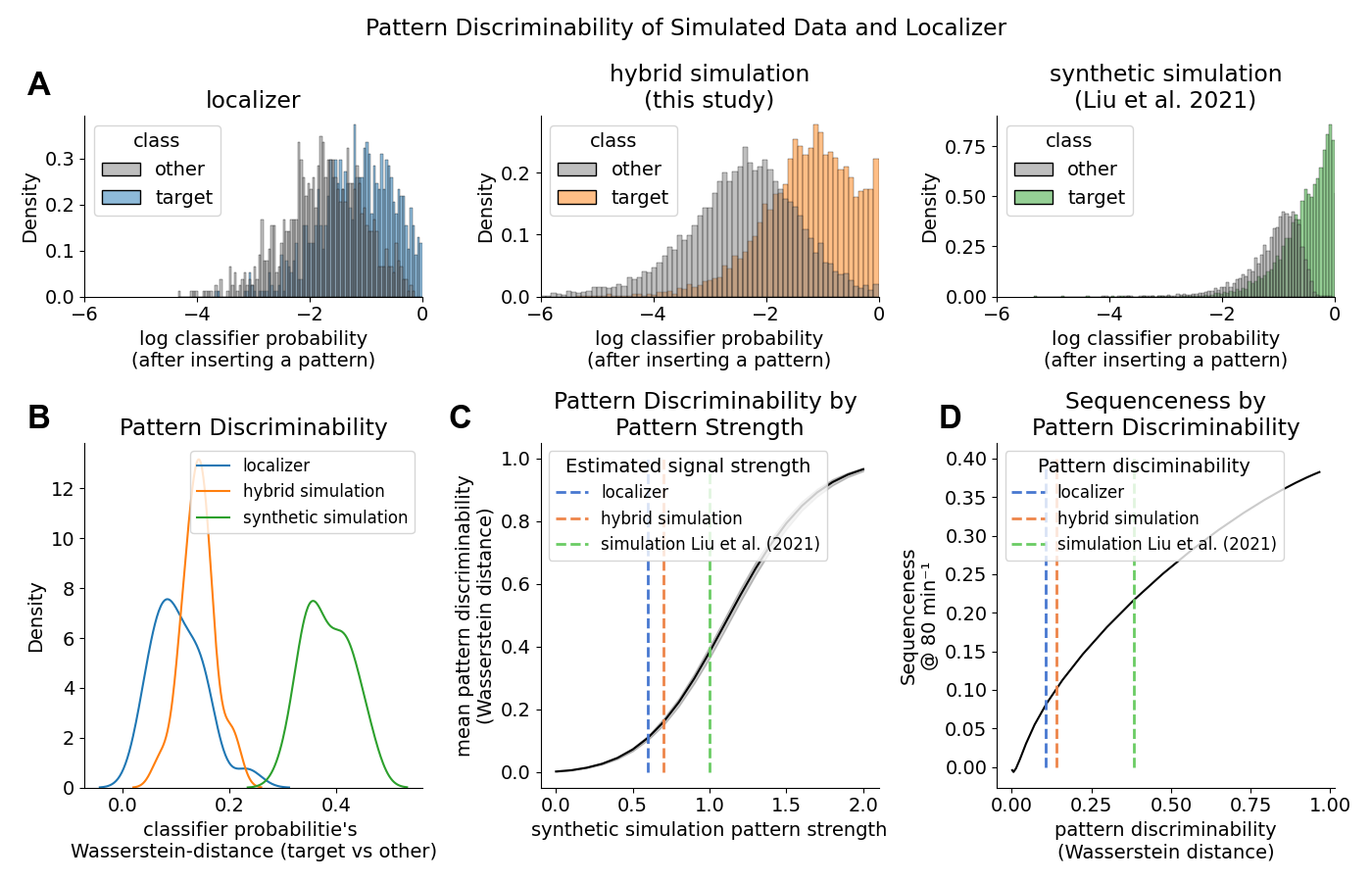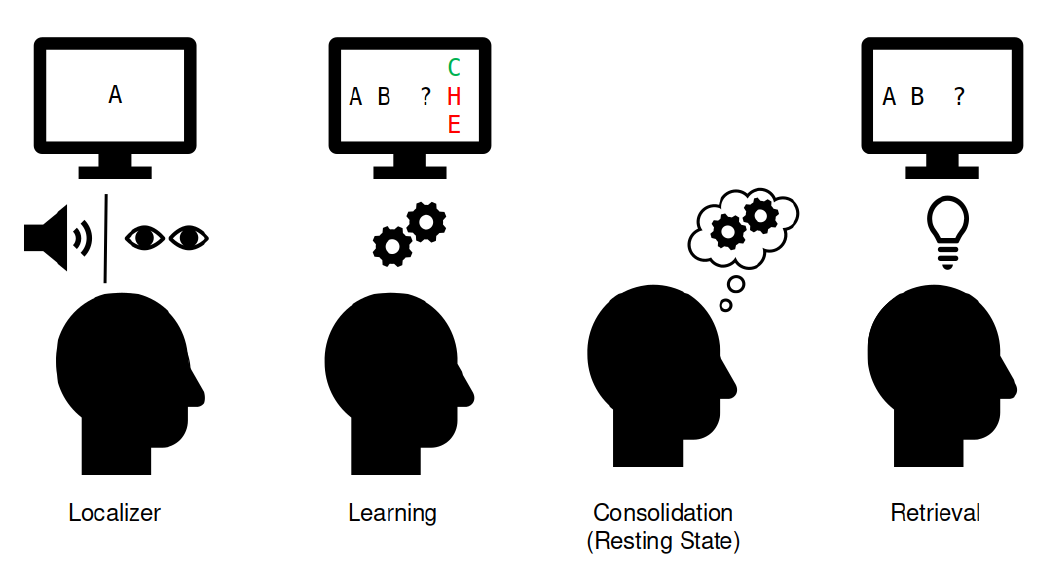




Localizer: Robust Decoders
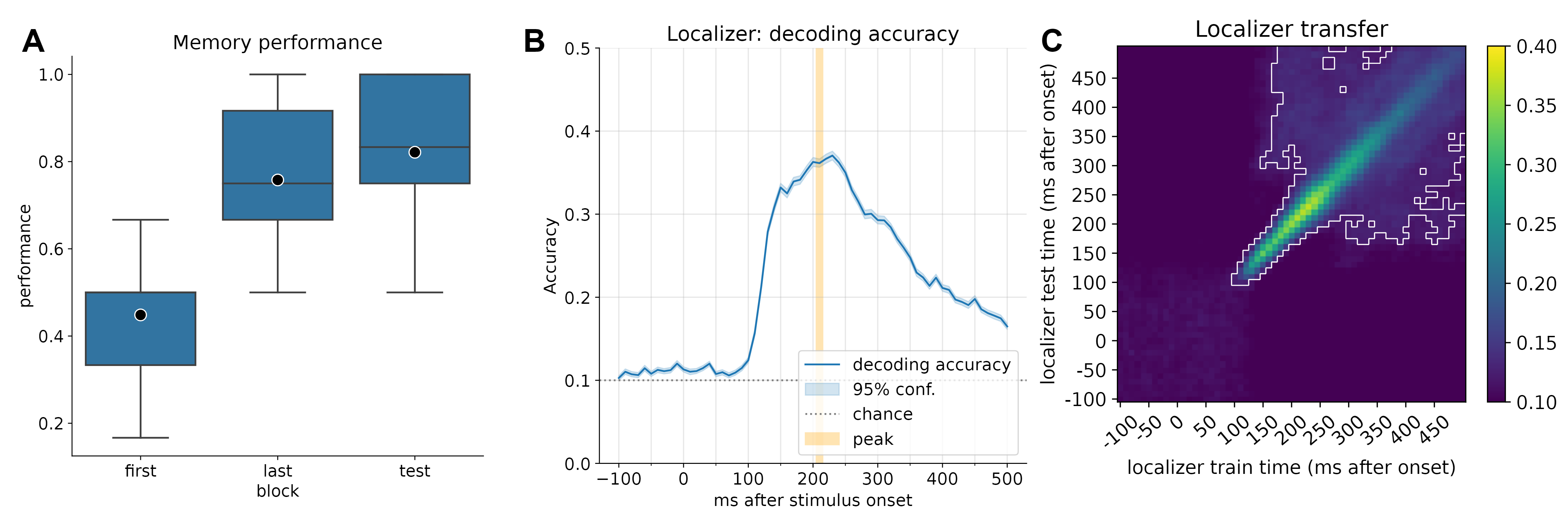
We determined the timepoint of best decoding accuracy by running a cross-validation across time. Peak decoding accuracy was at 42% accuracy (chance = 10%) at 210 milliseconds after stimulus onset. We trained one logistic regression classifier per class per participant on data from that timepoint (one-vs-all classification).